仅以此文记录深度学习入门过程。
介绍
深度学习(Deep learing)是近几年比较火的一个概念,而验证码安全在web安全中也有着重要的地位,那么本文将二者结合,将验证码的识别,作为深度学习的一个入门。
工欲善其事必先利其器,在这里介绍一个谷歌研发的开源机器学习框架—Tensorflow
开工
1. 数据预处理
- 数据准备
首先准备大量的图片验证码,将其分为训练集和验证集。
六万验证码 网盘密码d3iq
训练集用于神经网络的训练,验证集用于验证正确率。- 为什么要分开 ??
否则会造成污染,导致模型已认识这个数据了
- 为什么要分开 ??
数据处理
图片处理
标签处理 —>标签向量化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28def text2vec(text):
"""
文本转向量
Parameters:
text:文本
Returns:
vector:向量
"""
if len(text) > 4:
raise ValueError('验证码最长4个字符')
vector = np.zeros(4 * 63)
def char2pos(c):
if c =='_':
k = 62
return k
k = ord(c) - 48
if k > 9:
k = ord(c) - 55
if k > 35:
k = ord(c) - 61
if k > 61:
raise ValueError('No Map')
return k
for i, c in enumerate(text):
idx = i * 63 + char2pos(c)
vector[idx] = 1
return vector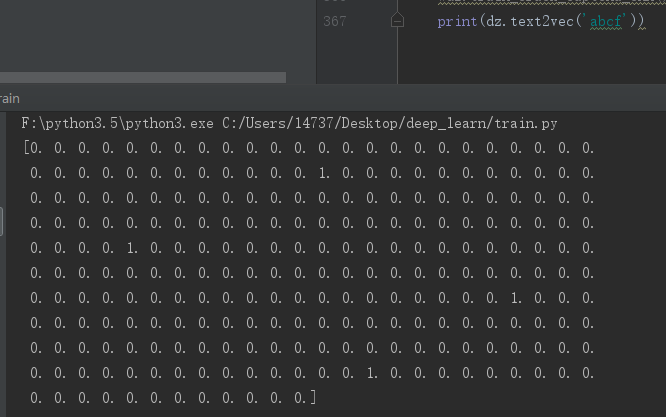
2.CNN卷积神经网络
通俗理解
- 特点:卷积神经网络引入卷积核解决图像数据非常大而产生的网络参数非常大问题。
卷积神经网络组成
1 | 卷积层(Convolution) |
- 卷积层
卷积核
一个有着固定取值的卷积核对图像矩阵进行扫描

在图像识别领域,卷积神经网络中的卷积核(滤镜)要实现的就是,将图像中的特征提取出来。
在最初的卷积层中,成千上万的神经元充当第一组过滤器,搜寻图像中的每个部分和像素,找出模式(pattern)。随着越来越多的图像被处理,每个神经元逐渐学习过滤特定的特征,这提高了准确性。
比如图像是苹果,一个过滤器可能专注于发现“红色”这一颜色,而另一个过滤器可能会寻找圆形边缘,另一个过滤器则会识别细细的茎。卷积层就是通过将图像分解成不同的特征来做这件事的。
具体怎么提取?
以猫为例,显著特征是圆眼睛三角耳朵尖下巴,但是总体来说狐狸也长这个样子,只是耳朵更大,下巴更尖而已。这些细小的区别很难描述。
- 池化层
整个图像中的这种“卷积”会产生大量的信息,这可能会很快成为一个计算噩梦。
为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling)
进入池化层,可将其全部缩小成更通用和可消化的形式。有很多方法可以解决这个问题,但最受欢迎的是“最大池”(MaxPooling)
- 全连接层
全连接就是个矩阵乘法,相当于一个特征空间变换,可以把有用的信息提取整合。全连接层一般在卷积网络的最后。
当然通过这些特征得到的结果不一定是正确的,因此需要一个‘反向传播的过程’对得到的结果进行‘纠正’。
反向传播将反馈发送到上一层的节点,告诉它答案差了多少。然后,该层再将反馈发送到上一层,再传到上一层,直到它回到卷积层,来进行调整,以帮助每个神经元在随后的图像在网络中传递时更好地识别数据。
这个过程一直反复进行,直到神经网络以更准确的方式识别图像中的苹果和橘子,最终以100%的正确率预测结果——尽管许多工程师认为85%是可以接受的。这时,神经网络已经准备好了,可以开始真正识别图片中的苹果了。
- 代码实现 3卷积层+1全连接层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76def crack_captcha_cnn(self, w_alpha=0.01, b_alpha=0.1):
"""
定义CNN
Parameters:
w_alpha:权重系数
b_alpha:偏置系数
Returns:
out:CNN输出
"""
# 卷积的input: 一个Tensor。数据维度是四维[batch, in_height, in_width, in_channels]
# 具体含义是[batch大小, 图像高度, 图像宽度, 图像通道数]
# 因为是灰度图,所以是单通道的[?, 100, 30, 1]
x = tf.reshape(self.X, shape=[-1, self.heigth, self.width, 1])
# 卷积的filter:一个Tensor。数据维度是四维[filter_height, filter_width, in_channels, out_channels]
# 具体含义是[卷积核的高度, 卷积核的宽度, 图像通道数, 卷积核个数]
w_c1 = tf.Variable(w_alpha*tf.random_normal([3, 3, 1, 32]))
# 偏置项bias
b_c1 = tf.Variable(b_alpha*tf.random_normal([32]))
# conv2d卷积层输入:
# strides: 一个长度是4的一维整数类型数组,每一维度对应的是 input 中每一维的对应移动步数
# padding:一个字符串,取值为 SAME 或者 VALID 前者使得卷积后图像尺寸不变, 后者尺寸变化
# conv2d卷积层输出:
# 一个四维的Tensor, 数据维度为 [batch, out_width, out_height, in_channels * out_channels]
# [?, 100, 30, 32]
# 输出计算公式H0 = (H - F + 2 * P) / S + 1
# 对于本卷积层而言,因为padding为SAME,所以P为1。
# 其中H为图像高度,F为卷积核高度,P为边填充,S为步长
# 学习参数:
# 32*(3*3+1)=320
# 连接个数:
# (输出图像宽度*输出图像高度)(卷积核高度*卷积核宽度+1)*卷积核数量(100*30)(3*3+1)*32=100*30*320=960000个
# bias_add:将偏差项bias加到value上。这个操作可以看做是tf.add的一个特例,其中bias是必须的一维。
# 该API支持广播形式,因此value可以是任何维度。但是,该API又不像tf.add,可以让bias的维度和value的最后一维不同,
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
# max_pool池化层输入:
# ksize:池化窗口的大小,取一个四维向量,一般是[1, height, width, 1]
# 因为我们不想在batch和channels上做池化,所以这两个维度设为了1
# strides:和卷积类似,窗口在每一个维度上滑动的步长,一般也是[1, stride,stride, 1]
# padding:和卷积类似,可以取'VALID' 或者'SAME'
# max_pool池化层输出:
# 返回一个Tensor,类型不变,shape仍然是[batch, out_width, out_height, in_channels]这种形式
# [?, 50, 15, 32]
# 学习参数:
# 2*32
# 连接个数:
# 15*50*32*(2*2+1)=120000
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
w_c2 = tf.Variable(w_alpha*tf.random_normal([3, 3, 32, 64]))
b_c2 = tf.Variable(b_alpha*tf.random_normal([64]))
# [?, 50, 15, 64]
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
# [?, 25, 8, 64]
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
w_c3 = tf.Variable(w_alpha*tf.random_normal([3, 3, 64, 64]))
b_c3 = tf.Variable(b_alpha*tf.random_normal([64]))
# [?, 25, 8, 64]
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
# [?, 13, 4, 64]
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# [3328, 1024]
w_d = tf.Variable(w_alpha*tf.random_normal([4*13*64, 1024]))
b_d = tf.Variable(b_alpha*tf.random_normal([1024]))
# [?, 3328]
dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]])
# [?, 1024]
dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d))
dense = tf.nn.dropout(dense, self.keep_prob)
# [1024, 63*4=252]
w_out = tf.Variable(w_alpha*tf.random_normal([1024, self.max_captcha*self.char_set_len]))
b_out = tf.Variable(b_alpha*tf.random_normal([self.max_captcha*self.char_set_len]))
# [?, 252]
out = tf.add(tf.matmul(dense, w_out), b_out)
# out = tf.nn.softmax(out)
return out

